Why do we need a Data Platform?
At Ripple, different business units require a platform to quickly and easily turn their data into insights and compelling customer experiences. For Ripple's product capabilities, the Payments team of Ripple, for example, ingests millions of transactional records into databases and performs analytics to generate invoices, reports, and other related payment operations.
A lack of a centralized system makes building a single source of high-quality data difficult. It can lead to expensive, slow, and unmaintainable systems. The key aspect of any business-centric team in delivering products and features is to make critical decisions on ensuring low latency, high throughput, cost-effective storage, and highly efficient infrastructure. Multiple data processing systems also make building detailed dashboards and monitoring very difficult.
Why is it difficult to build a centralized platform?
Data can come from different sources—streaming vs. batch, internal vs. external, and application vs. databases. There are varying requirements for latency and payload size. Large volumes of data need to be handled efficiently without surging costs or latencies. There need to be precise access controls and guardrails for data quality. Last but not least, the user experience for pushing in data and pulling out insights needs to be easy and secure. These aspects bring in a number of process and engineering challenges that need to be solved; some of our design tenets aim to address these effectively.
The Ripple Data Platform
Ripple’s internal data platform allows teams at Ripple to analyze their data quickly and easily for any volume of data. They can ingest and transform their data efficiently from any global location in a primarily self-service way and generate insights within seconds.
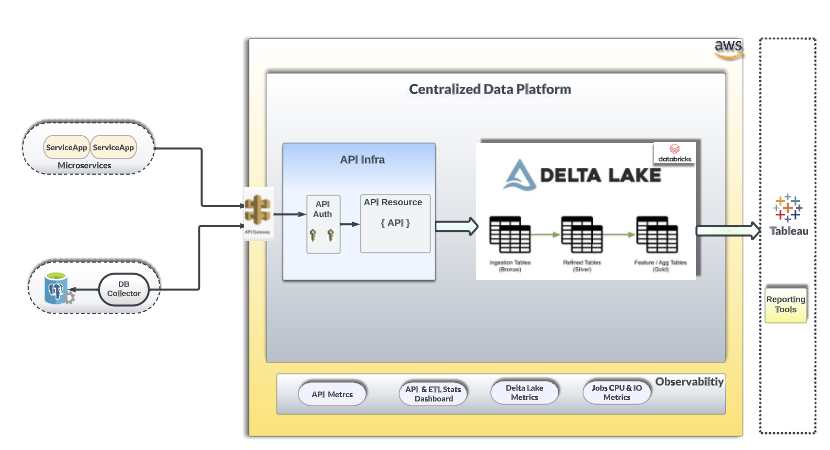
The figure below depicts a simplified view of the Ripple Data Platform, built on Databricks, running on the AWS cloud. Data from Ripple Producers is fed via Databricks’ Spark engine into the Delta Tables, landing in a raw ‘Bronze’ stage, which is then cleaned and transformed into Silver and Gold stages.
How does Data Platform provide APIs for Ingestion and Lookup?
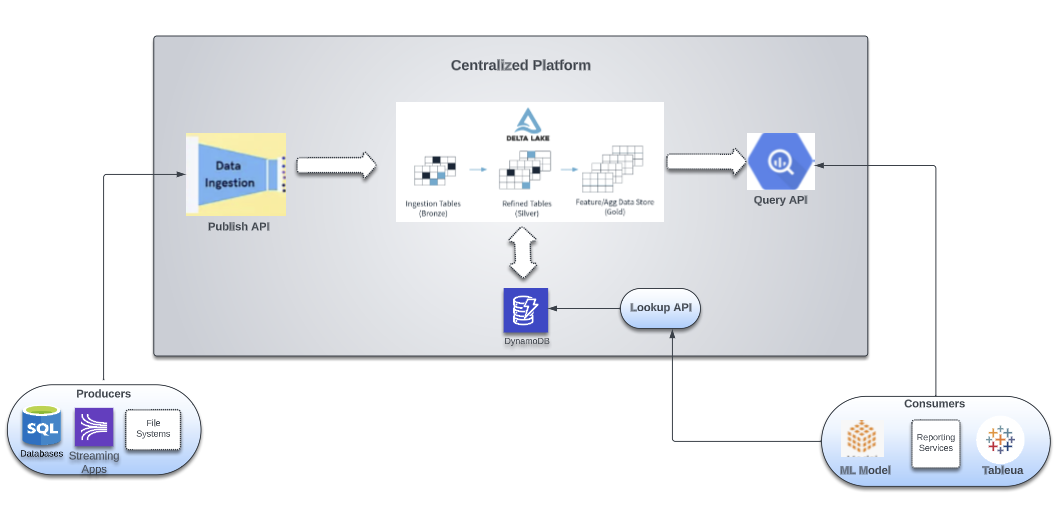
The Ripple Data platform provides multiple APIs to enable Ripple Data Producers and Consumers to build their use cases. Multiple APIs provide an easy-to-use interface that allows self-service data loading into the Lakehouse for Ripple Data Producers and a lookup query mechanism for Ripple Data Consumers.
There are three core APIs:
- Ingestion from applications in near real-time
- Querying Lakehouse data in a scalable way by applications
- Lookup API for pulling real-time data updated from the Lakehouse into scalable NOSQL stores
The APIs help:
- abstract the underlying infra complexity and provide simplified schema-based Ingestion using a secured token mechanism.
- Ripple Data Producers to ingest data from any source into the lake storage following a unified schema pattern avoiding multiple platforms for ingestion sources.
- Ripple Data Consumers query the data from the lake storage using the SQL strategy.
- scale automatically to handle the amount of requests traffic, enabling throttling and cache mechanism, which allows Ripple Data Producers and Consumers to ingest and query any volume of data.
How have teams used Data Platform at Ripple?
With the self-service API mechanism, Data Platform has enabled different teams to ingest, store and analyze data efficiently. This is helping teams accelerate their application development and derive key insights from their data; we are already seeing efficiencies from teams not having to deal with service setup, integration, and account access:
- The Payments Organization developed a Real-Time Dashboard using the self-serve APIs for ingesting and querying data. The dashboard delivers liquidation data in real-time, giving Ripple the ability to understand real-time corridor capacity to anticipate and prevent liquidation failures and hedge financial risk.
- The Liquidity team developed dashboards for analyzing the customer wallet balances using Data Platform. Liquidity ingests the customer wallet data via self-service publish APIs, and data gets further analyzed at the platform’s Delta Lake to develop dashboards that provide Ripple’s finance team with an overview of balances related to customer wallets.
The Centralized Data Platform has been widely adopted within Ripple, enabling teams to plan and deliver product features more efficiently via self-service. We will continue to build speed, cost, and data quality improvements into the platform, along with new API abstractions such as Data Quality Validation API, Data Pipeline API, and Data Observability Dashboards API and other APIs where appropriate, to support and scale Ripple teams’ growth.