Introduction: Embracing the Future with Ripple's Data Platform Migration
Welcome to a pivotal moment in Ripple's data journey. As leaders at the intersection of blockchain technology and financial services, we're excited to share a transformative step in our data management evolution. We recently embarked on a significant data platform migration, transitioning from Hadoop to Databricks, a move motivated by our relentless pursuit of excellence and our contributions to the XRP Ledger's (XRPL) data analytics.
Our new system on Databricks stands as a beacon of innovation, shedding the constraints of our legacy Hadoop system and embracing the efficiency and power of a unified analytics platform.
Ripple's Journey and Challenges with the Legacy System
Our legacy system was once at the forefront of big data processing, but as our operations grew, we faced a tangle of complexities. High maintenance costs and a system that struggled to meet the real-time demands of our data-driven initiatives. The legacy Hadoop system became synonymous with delayed projects and a burgeoning need for specialized personnel to maintain its sprawling infrastructure.
Evaluating the Contenders
We needed a solution that not only resolved our current challenges but also positioned us for future innovations. After evaluating numerous data solution providers, Databricks stood out due to its seamless performance and lakehouse capabilities, which offer the best of both data lakes and data warehouses.
Why Databricks Emerged as the Top Contender
1. Because we have a wide range of teams that need to use our data platform solution — including machine learning teams who want to train large models and run hundreds of experiments, analytics teams who need to run many dashboards and integrate with Tableau, and core engineering teams who want flexible Extract, Transform, and Load (ETL) Pipeline solutions — any platform we chose needed to be able to handle all these different use cases without stitching together disparate services.
2. We envisioned a system that would enable Ripple to achieve low-latency pipelines and use cases. Specifically, we wanted to be able to get to less than five seconds end-to-end streaming latency with complex ETL aggregations and data in the order of hundreds of terabytes. Benchmarking with Databricks and Delta Live Tables showed that we were able to achieve the vision we wanted while competitors fell flat, and we're constantly working with the Databricks Solutions Architects team to optimize further.
3. Our existing architecture, based primarily on a Hadoop stack, and our data operations were beginning to show signs of strain, particularly in terms of cost and stability, as we scaled up. Databricks' prior successes working with customers on multi-PB deployments (including those that migrated from Hadoop) were a key contributor to our purchasing decision because we know that our data lake will only continue to grow as more teams adopt our new unified Lakehouse.
Databricks presented itself as a unified platform adept in data engineering, analytics, and machine learning, addressing all our data processing requirements. The integration of Apache Spark for complex data handling and enhanced security features further affirmed Databricks as Ripple's optimal choice.
The XRPL System on Databricks
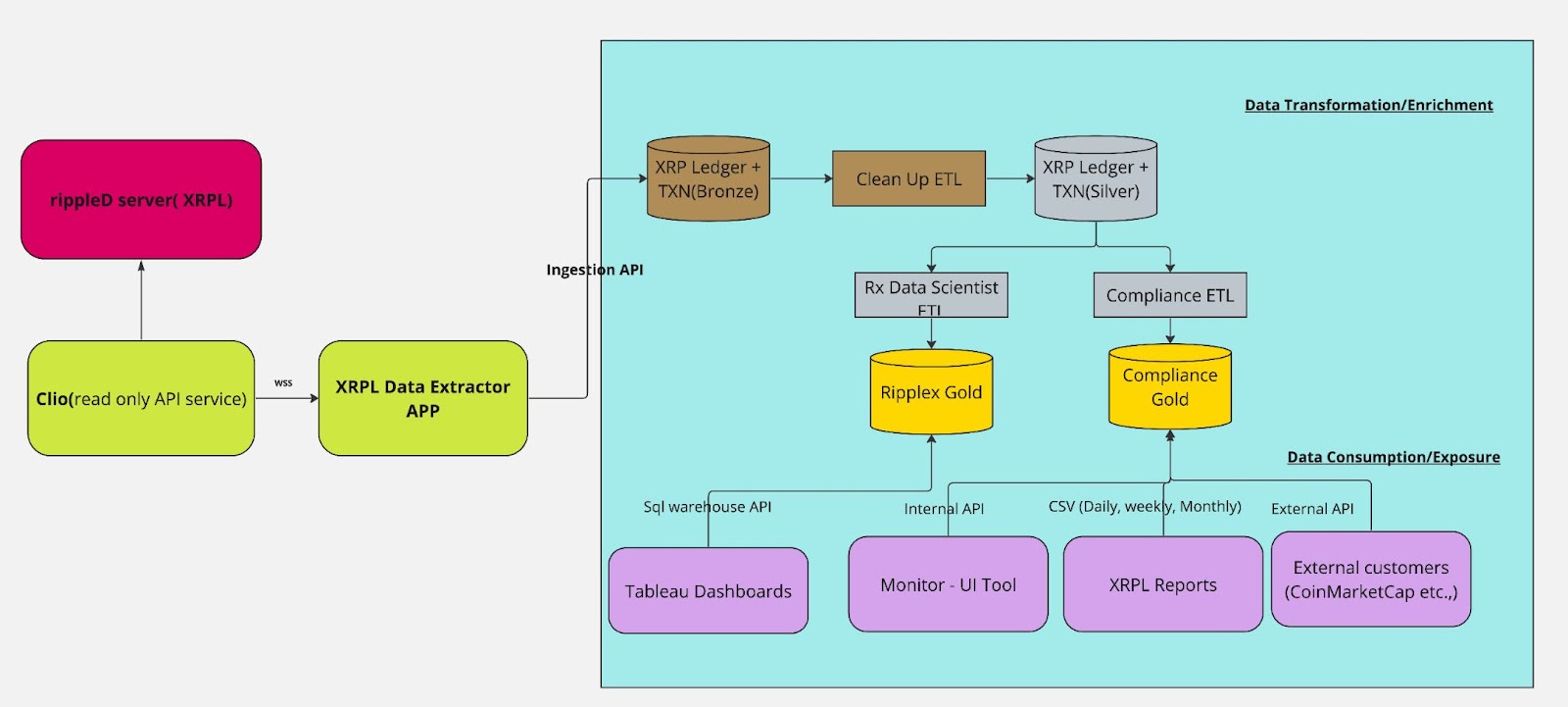
At the heart of our data ecosystem lies the rippled server, the core engine driving the XRPL. Data flows from this central node through Clio, our read-only API service, ensuring secure and efficient data retrieval. This vital information then streams to the XRPL Data Extractor App. This pivotal component interfaces with the XRPL via a WebSocket secure connection (WSS), marking the beginning of our data journey.
Upon extraction, the raw data enters the 'Bronze' stage through the Ingestion API, where it is stored as our initial, unprocessed dataset. In the subsequent Clean Up ETL phase, data begins to take shape—cleansed, transformed, and enriched, transitioning into the 'Silver' tier, a more refined and structured state ready for further analysis and enrichment.
Diverging from this point, the data advances along two critical paths. One leads to the Data Scientists for in-depth analysis, feeding into the 'Ripplex Gold' repository, where data reaches its zenith in quality and analysis readiness. Simultaneously, the Compliance ETL process channels another stream of data into the 'Compliance Gold' layer, specifically optimized for regulatory and compliance activities, including rigorous AML transaction monitoring for Ripple Payments.
The downstream flow of data is multifaceted: Through the SQL warehouse API, insights are visualized on Tableau Dashboards, enhancing our internal reporting and monitoring capabilities. The Internal API serves as the backbone for operational tools, while compliance reports are generated in various formats to meet daily, weekly, and monthly reporting requirements.
Externally, our APIs disseminate XRPL Reports and provide data to esteemed partners and platforms such as CoinMarketCap, which is critical in accurately portraying XRPL data.
Cost and Performance
The numbers are striking. Our total processing time for end-of-day batches has dropped from 410 minutes to a mere 42 minutes–that's a 90% improvement. We've also achieved a 77% reduction in cost. The system's efficiency is further underscored by an 84% decrease in the total number of tables and a 55% reduction in the total GB ingested per day.
Operational Impacts: Ripple's Renaissance
This migration's impact has affected many facets of our operations. The transition to Databricks has empowered our Ripple Global Investigations team, enhancing their capabilities in conducting AML Transaction Monitoring. Our reports to finance teams are now more timely and accurate, bolstering trust and reliability in our data.
Additional Advantages of the Migration
Beyond the impressive performance and cost metrics, our move to Databricks has armed us with additional strategic advantages:
- Scalability and Flexibility: The Databricks platform, with its elastic resources, allows us to scale up or down effortlessly, ensuring we're always at the optimal balance of performance and cost.
- Advanced Analytics and Machine Learning: We can now leverage the full spectrum of
machine learning and advanced analytics capabilities, accelerating our journey toward predictive and prescriptive insights.
A Vision for the Future
With this advanced infrastructure, we're now more agile, more responsive, and more prepared than ever to meet the challenges and opportunities of the future.
Our Data Engineering team is exploring deeper integrations with AI and machine learning, which promise to unlock even more value from the XRP Ledger data. We're also looking at expanding our analytics offerings, providing more sophisticated tools and insights to our clients and stakeholders.
Conclusion
This migration transcends Ripple's internal workings; it has the potential to reshape how we interact with our partners and the broader financial industry. With faster processing times, more accurate data, and reduced costs, we continue to innovate and push the boundaries of what's possible. We look forward to sharing our learnings and successes with the community, driving the entire sector toward a more data-informed and efficient future.