One of the perks of being an engineer at Ripple is working with one of the greatest minds in blockchain—David Schwartz aka JoelKatz. Even though he’s always up for a lively discussion, as our CTO, David has a packed schedule: working to improve the XRP Ledger, helping steer the direction of RippleNet products and services and speaking all over the world as an industry leader. For this past April Fools’ Day, we took a stab at making David’s unique perspective and knowledge available 24/7 across the company in the form of /joelkatz, a Slackbot.

The Challenge
Like most April Fools’ Day ideas, we only thought of creating a /joelkatz bot in late March. The general idea was to have an interactive bot that responded to questions with David’s style of writing. With such a short lead time, we wanted something that wasn’t complicated but was still real enough to be fun. A slackbot made the most sense, since Slack is widely used across the company and provides a great SDK for building custom commands. But building a model to interpret a question and generate a response was not feasible. Instead, our minimal effort approach was to ignore the actual question posed and just generate a “JoelKatzism” in response. Fortunately, we were lucky that David has a rich corpus of short written text in the form of his tweets. Armed with this data set and with April 1 fast approaching, we got to work.
Generating JoelKatzisms
Generating a JoelKatzism (JKizm) can be viewed as a statistical modeling problem. If we knew the set of all possible JKizms and the probability of each, generating one would simply require sampling that distribution. But how do we define JKizms? One simple, but unexciting model, is to take David’s existing tweets as the set of possible JKizms, with each occurring with equal probability. In python,
JKizms = [line.strip() for line in open("src.txt","r")]
random.choice(JKizms)
# Wow! They clearly understand what really matters in this space! If you
# can't change quickly, how can people rely on you?
This works but can only generate phrases David actually wrote. We want a bit more variety.
For a slightly more sophisticated model, we can define JKizms as sequences of words, where the probability of an individual word is defined by the frequency it occured in David’s tweets.
First, we need a way to split each tweet into words:
start = "<<START>>"
end = "<<END>>"
def to_words(line):
return [start] + line.split(" ") + [end]
For later, we also add special start and end symbols to each tweet.
Finding the distribution of words is simply counting them across all of the tweets
counts = defaultdict(int)
for izm in JKizms:
for word in to_words(izm):
counts[word] += 1
dist = pd.DataFrame(counts.items(), columns=['Word','Count'])
dist above is a pandas DataFrame, with each row describing a word and the count of times it occurred in David’s tweets. We can generate a phrase by repeatedly sampling from dist, terminating when we hit the special stop symbol:
res = []
while True:
word = dist.sample(weights='Count')['Word'].iloc[0]
if(word == end): break
res.append(word)
" ".join(res)
# with them, using is IMO, is repeating this strictly his entity ...
This is a bit better, but the novelty of phrases is overshadowed by the lack of realism. Not surprisingly, concatenating random words generates mostly gibberish. The words in actual sentences rely on each other to provide meaning.
Adding this structure is fairly straightforward-we make the probability of selecting a word conditional on the prior word selected. First, we need a way to find all pairs of words:
def to_pairs(words):
""" Split a line into successive pairs of words"""
return [
{"First": f, "Second": s}
for f, s in zip(words[:-1], words[1:])
]
Then we sweep through the entire corpus of David’s tweets to get the distribution of pairs of words.
raw = pd.concat((pd.DataFrame(to_pairs(to_words(izm))) for izm in JKizms))
dist = (
raw.groupby(["First", "Second"])
.size()
.reset_index()
.rename(columns={0: "Count"})
)
Now each row of dist is the count of times the Second word occurred after the First. To generate a phrase, we begin with the start symbol, but now sample the second word from the subset of rows which have First word as <<START>>. We repeat this process until we hit the end symbol.
res = []
last = start
while True:
word = (
dist.loc[dist["First"] == last]
.sample(weights="Count")["Second"]
.iloc[0]
)
if word == end:
break
res.append(word)
last = word
" ".join(res)
Not too bad for a few lines of python! This procedure of sampling the next word based on the prior word is the defining feature of a Markov chain, a simple but powerful approach to modeling random processes. Outside of the fun use case here, Markov processes show up in a wide variety of contexts, ranging from PageRank to speech recognition to Bayesian inference.
It's alive!!
Now that we know how to generate JoelKatzisms, creating the JoelKatzBot was only a few extra steps away. First, rather than using our bespoke python code above, we actually relied on the great markovify python library. Out of the box, it more cleanly tokenizes David’s source tweets and tries to ensure generated phrases are novel. Second, we chose Google cloud functions as a cost-effective, serverless approach to generating JoelKatzBot responses. Even easier, there is a tutorial on how to use cloud function’s with Slack.
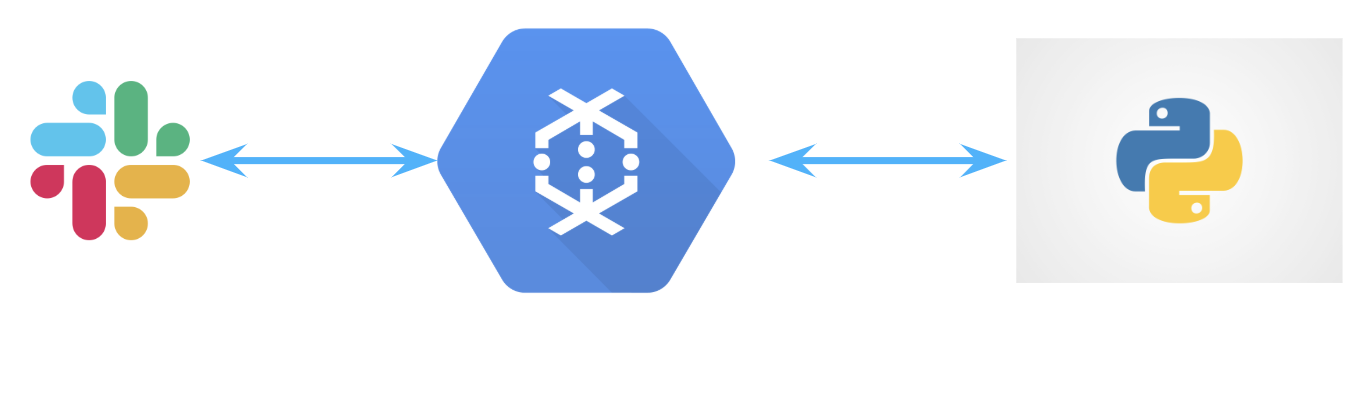
Without further ado ...
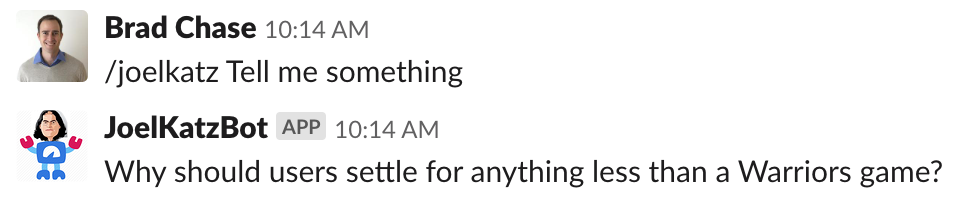
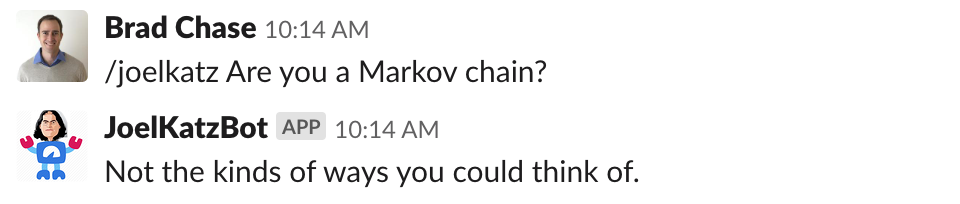

Suffice it to say, it was a big hit. Even our CEO, Brad Garlinghouse got in on the fun:
Interested in working with the real JoelKatz? Click below!