Background
Hi, I’m Andrew Hoffman, a Senior Staff Security Engineer on Ripple’s Product Security team. My team is making use of a process known as threat modeling in order to assist our software engineers in building more secure products and features. My hope is that by the end of this post you'll not only have gained insight into Ripple’s threat modeling methodology, you’ll also have developed a sense of why threat modeling is important and how an effective threat modeling workflow can be developed.
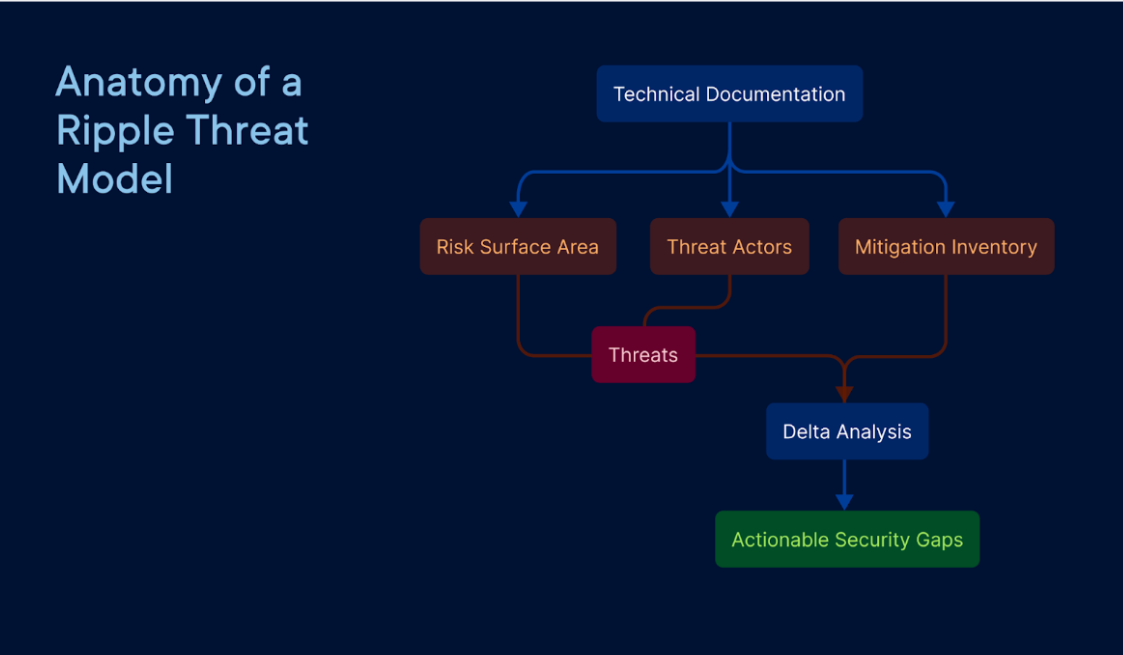
Anatomy of a Threat Model
Many software companies that have invested in information security have attempted to build threat model documents in order to gain insight into the security posture of their products and features.
Threat model documents are the output of a threat modeling exercise. I like to distinguish between the two because the reality is that the document itself should just be a summary of the process and findings from the threat modeling exercise.
Many companies use an open source methodology for performing a threat modeling exercise such as STRIDE, PASTA or VAST. At Ripple, we have adopted a threat modeling methodology that is loosely based on PASTA but flexible enough to be deployed rapidly and structured with emphasis on actionable results. Later on, I’ll dive deeper into the reasons flexibility and speed are important factors in threat modeling at Ripple.
Below, I outline the seven phase process that our threat modeling workflows are built upon.
Phase #1: Software Development Lifecycle (SDLC) Integration
Our threat modeling workflow is baked tightly into our software development lifecycle (SDLC). This enables threat models to be kicked off routinely as part of a standard process, rather than having to be initiated on a one-off basis.
At Ripple, threat models are kicked off during the architecture design phase which is an early stage within our SDLC at which engineers build a product requirements document (PRD) followed by a technical design document (TDD). These documents describe how the new product or feature is intended to be built, prior to any code actually being written.
By following specific templates and collaborating with a security engineer, these two documents often contain the majority of information needed to initiate the threat modeling process. Once a security engineer has confirmed this is the case, then phase two begins.
Phase #2: Technical & Risk Documentation
There are two primary goals within phase two of the threat modeling exercise, both of which are recorded via the technical & risk documentation section of the threat model.
First, I want to obtain intimate familiarity with the product or feature being built so I can understand more deeply the ways in which the design of the software may be lacking. In order for this to occur, technical documentation and information from multiple sources must be consolidated in a way that makes it easy to find security relevant documentation. Second, I want to begin using the newly consolidated technical documentation to begin finding high risk surface areas (areas likely to be targeted by attackers) within the new product or feature. Often high risk surface areas include complex business logic, changes to cryptography or security controls, API calls that result in the movement of customer funds, and functions that interact with personal identifier information (PII).
I will denote key technical details and high risk surface areas in the first section of the threat model document. This has the added benefit that going forward other security engineers can simply read the threat model’s technical documentation subsection and quickly become familiar with the most security-relevant details.
Phase #3: Threat Actors
After the security-relevant technical documentation has been copied into the threat model document, the next phase in the threat modeling exercise is to come up with a list of threat actors. Threat actors are all of the humans (and in some cases machines) who have access to systems within the new product or feature.
This step is skipped in many threat modeling methodologies, but we believe it to be crucially important because of the fact that not all vulnerabilities can be exploited by all users.
We document each threat actor alongside their permissions in a table, which will later on be referenced whenever a security gap or vulnerability is found in this application.
Phase #4: Threat Identification
In this phase, I analyze the content of the technical documentation section and cross reference it with the threat actors section. From the content of these two sections we can identify security gaps which we call threats.
Because we perform threat modeling prior to writing code, most threats are either misconfigurations or business logic vulnerabilities. Whenever a security misconfiguration is found, we not only document it in the threats table of the threat model but also add it to a dictionary of common security misconfigurations so future threat models can easily use it as a reference.
Business logic vulnerabilities, on the other hand, are generally specific to a particular application and, as a result, not as applicable to all future applications. We document these in the threats table, but do not add them to a centralized repository of issues. When the threats table is completed, each threat is tied to the threat actors who could exploit it, and the process moves to phase five.
Phase #5: Mitigation Inventory
The mitigation inventory is a commonly overlooked but essential component of a threat model. For each threat identified in phase four, we attempt to look for existing mitigations (partial or complete fixes). We record each mitigation found, so we can later map mitigations to vulnerabilities and see if any outstanding vulnerabilities may already have a fix in place.
This is an important step for several reasons. First, if a full mitigation already exists for a threat, the threat is not exploitable. Adding a duplicate or additional mitigation often results in unnecessary engineering work and can cause complications in the future.
Additionally, the mitigation inventory becomes a useful reference later on when code is written and the application is deployed to production. If future updates cause worry of vulnerabilities, this section can be used as a reference to quickly determine if a potential vulnerability is actually exploitable. This also saves time in regards to penetration tests and bug bounty programs by having all known mitigations in a centralized location.
Phase #6: Delta Analysis
Next, we cross-reference the threat table and mitigation inventory table. Doing so allows us to determine what threats are relevant and which threats are already accounted for. Generally speaking, it is often the case that a threat will not have a full mitigation but instead a partial mitigation. In these cases — and in the cases where no mitigation exists — the security engineer developing the threat model will work with the engineering team to come up with comprehensive mitigations. When multiple similar mitigations are identified, we provide the engineering team with a cost-benefit analysis that considers multiple factors including time, costs and usability.
Phase #7: Remediation
At this point in time, the threat model exercise and document are finished. The threat model will remain a living reference document (updated periodically based on certain criteria), but the next actionable step is for the threats found to be remediated.
At Ripple, we make use of a service-level agreement (SLA) which defines the speed at which a vulnerability must be remediated based on severity. We enforce this SLA on post-production security threats which we call security bugs, but allow pre-production security threats (we call them security requirements) to be resolved without SLA, provided the application is not yet moved into production (in which case the threat converts automatically to a security bug). Our goal is to fix all security bugs prior to production, so this conversion doesn’t have to take place and is instead a fail-safe mechanism.
We track remediation of all of these security requirements (and bugs) on Jira, and make use of automation to assist in bringing in the correct stakeholders and holding them accountable for agreed upon remediation timeframes.
Summary
By closely following this threat modeling workflow for each new product and feature launched by Ripple, we are able to identify and resolve the majority of misconfigurations and business logic vulnerabilities prior to any code being written or any applications being deployed.
Threat modeling has become a core component of our security workflows and assisted us in shipping dramatically more secure applications than we could have otherwise.
By combining threat modeling and other security processes, we are able to deliver products in a way such that our customers can rest assured that security due diligence has been performed.


