Why use retry logic?
At Ripple we create and maintain a large set of micro-services that interact over network resources to solve customer needs. Although networks are mostly stable, services need to code defensively against potential short network outages. For example, a network blip could disrupt communication between two micros-services, or between a micro-service and a backing store, such as a database. In such scenarios, retrying a request would make sense, as it would improve the resiliency of the service.
What to consider before adding retry logic?
When looking at adding a retry mechanism there are several things to consider. Not all errors would benefit from a retry. An obvious example where retry does not help is when required arguments are omitted from a request. A more subtle example in a withdrawal scenario is when all arguments are supplied but the operation returns an error stating that the account does not have a sufficient balance. In this situation, if you simply retry an operation without adjusting the balance, you'll get a failure.
We need to divide possible error scenarios into two categories: those that could succeed after a retry and those that will fail after a retry.
We also need to consider how many times to invoke the retry logic and when. Does it make sense to retry an operation right away, or is it better to delay the retry? There are several commonly used delay policies:
- Fixed Backoff Policy – a fixed delay between each of the retry attempts. This is the simplest policy and is generally used for requests coming directly from a user who needs a quick response.
- Exponential Backoff Policy – a multiplier determines when to retry next. For example, if the multiplier is 2 and the initial delay is 1 second, we would retry the operation in 1 second, 2 seconds, 4 seconds, 8 seconds, etc. This is a more complex retry policy used to address network overload. At each point of failure, the exponential approach addresses the possibility that the issue is more severe, hence increasing the delay interval.
- Random Backoff Policy – Just as the name suggests, it randomly selects the delay at each point. Imagine 100 requests arriving at a service that can only handle 90 requests at a time. In such a scenario, the service might experience an outage and might have to be restarted. But if all 100 requests use either fixed backoff policy or exponential backoff policy, they would still arrive at the same time, causing the service to fail again. Implementing Random Backoff Policy allows the service to process the requests in smaller batches.
Not all requests can be retried. In fact, if the system processing requests is not idempotent, it is generally not a good idea to retry requests without knowing the state the system is in. This is especially true if the system was able to process your initial request but the response failed to reach your service. Consider a non-idempotent system that attempts to deduct money from an account. In this case, the retry operation might deduct the same charge multiple times. To avoid multiple charges, it’s important to check the status of the initial request before retrying.
On a similar note, we should also consider the two categories of retry operation: stateful and stateless. In stateless retry operations, the system does not have any side effects modifying the state, so it could be retried without any issues. But in an operation that has side effects, or that consists of multiple steps, a stateful retry mechanism is a much better fit. In such cases, you can either revert the side effects before retrying, or skip the steps that were successful and start the retry operation from the point of failure. If a given service requires stateful retries, usually a context object is used and updated during the runtime.
Retry Library Options
While there are many retry Java libraries equipped to handle the considerations above, here is a comparison of the 4 most popular Java libraries: Resillience4j, FailSafe, Spring Retry and Guava.
To compare these libraries, we created a very simple service that returns a set value but could also randomly throw an IO, Timeout, or SQL exception. Each library was configured so that it retries IO and Timeout exceptions up to 3 additional times, and stops retrying at any point in the case of an SQL exception. These specific exceptions were randomly picked to show that the library could be configured in a way that allows specific exceptions to be retried, while other exceptions result in failure right away. This allows us to discern between the errors that could be retried and those that do not benefit from retrying.
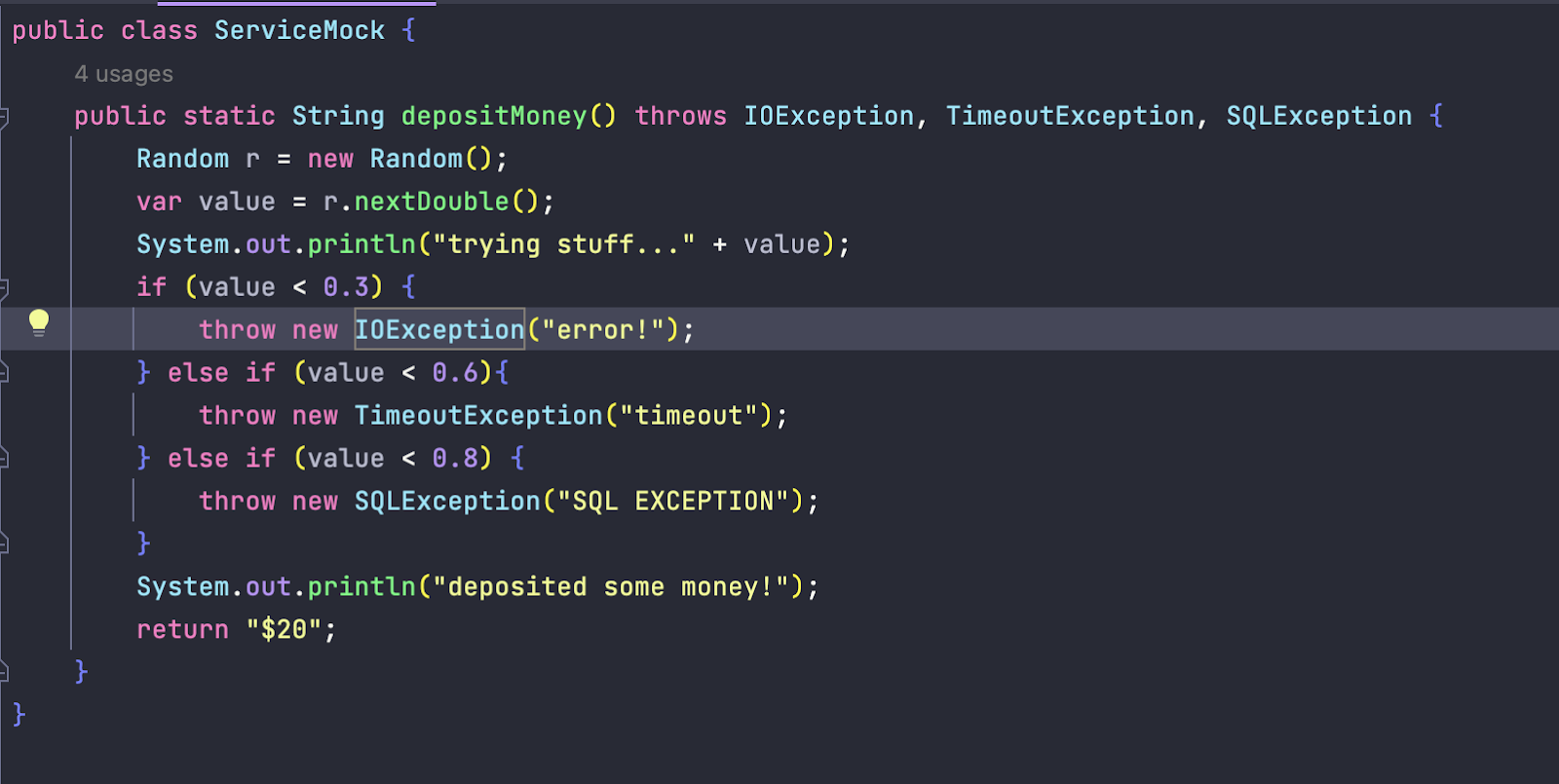
Setting Exception Policies & General Experience
As a baseline, all four of these libraries allow users to set policies regarding specific exceptions. In each of the examples below, we attempt to utilize the libraries' core policy functions to retry on IO and timeout exceptions. Each section below will cover a library’s exception policy handling, my personal experience with the library, as well as some of its key features.
Some of the key features that we look for when evaluating a retry library are:
- Thorough documentation and developer support on starting up, maintaining, and executing basic retries utilizing said library. This is important as we have engineers of all levels that could be utilizing this technology so ensuring developer-backed documentation is well organized and maintained is pertinent for knowledge density without loss of engineering resources.
- Support for customizing and configuring custom exception policies.
- Support for stateless vs stateful retries. All libraries we’re examining in this document are stateless by nature—which Ripple still has many use cases for—however, stateful retry support can contribute to successfully maintaining a state (and therefore accuracy) regarding retries in transactional use-cases.
Resilience4j
- Resilience4j offers the ability to configure custom exception policies through the RetryConfig global class. This makes it easy to set specific exceptions that the sample API may throw.
- Based on our experience, this library lacked good documentation, and the documentation we found left us guessing and trying things out. Most importantly, there was no documentation around built-in stateless vs stateful retries.
- One positive for this library is that it allows for modularization of Resilience4j features, meaning the library works independently of each feature and would be relatively lightweight as a dependency.

Spring Retry
- Spring Retry allows us to configure an exception policy using its RetryTemplate. It is easy and intuitive to set policies for specific exceptions (by simply passing in @Retryable to the service call and setting its values to the desired exceptions).
- The documentation was excellent, and this was the easiest library to get a sample retry mechanism working. Additionally, while the example doesn’t implement this, Spring allows its users to differentiate stateless and stateful retries for various business needs.
FailSafe
- Failsafe utilizes its RetryPolicy class to attach policy handling. Similar to Spring, it is easy and intuitive to set policies regarding specific exceptions.
- Failsafe has a fair amount of documentation and has good example code for its users to get started quickly.
- Failsafe doesn’t have any stateless vs stateful support.
Guava
- Guava allows policy handling based on exception types as well as an easy way to retry based on result types.
- It has excellent documentation, making the library easy to set up and use.
- Unfortunately, I couldn't find any support for stateless vs stateful functionality.
Runtime Impact of Adding a Retry Library
It’s important to consider runtime differences that each library adds to the total process execution. We estimated that such an impact is generally small, so in order to calculate accurately, we had to measure total time of multiple executions and then divide that time by the number of executions. Specifically, we measured the time it took for 100 calls to a sample service that never throws an exception, with and without a retry framework. The difference between these times divided by 100 measures the runtime impact of the library. As our local machine could be running background processes that could interfere with the measurements, we ran each test five times, so the average result would be a close approximation of real runtime impact. Below are the tables that describe our results:
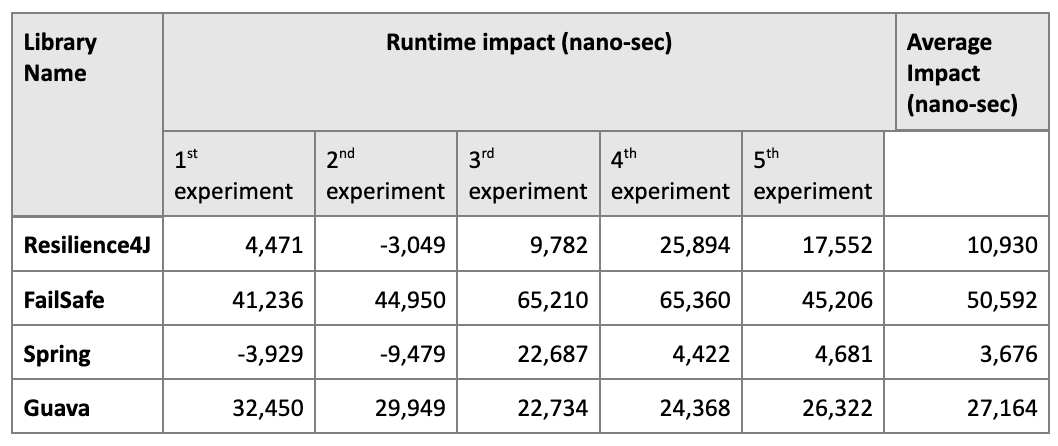
Note that sometimes runtime impact is negative, which highlights the challenges of observing tiny increments in runtime behavior compared to background processes that have significant impact on measuring outcomes. Yet, even with such outliers we can see the trends in how each of the libraries affect our runtime.
Conclusion
Retries dramatically improve service resilience, but there are a few key factors to consider while using a retry mechanism. We first started utilizing Spring retry in our workstream in the winter of 2022 which has improved our ability to deal with missing data and failed responses. Based on our experience, we would recommend using the Spring retry framework for current and future business endeavors.
