Summary
Managing the entire lifecycle of a machine learning (ML) model from inception to deployment in production can be a daunting task involving multiple systems and lots of moving parts. At Ripple we have a mix of cloud providers (GCP and AWS) and internally managed tools (Gitlab, Artifactory, Vault etc.), and we needed a managed solution that would help us deliver models to product use cases within a short amount of time, which led us to choose Databricks. This blog outlines Ripple’s general design and approach for machine learning model lifecycle management using Databricks.
Machine Learning at Ripple
Ripple’s enterprise-grade solutions allow customers to: source crypto, facilitate instant payments, empower their treasury, engage new audiences, lower capital requirements, and drive new revenue. We use machine learning to predict customer demand in global markets, execute orders intelligently on crypto exchanges and save on costs. As we’ve increased our investments in machine learning solutions, the applied science team has created many parts of the ML platform from scratch while figuring out how to make it work well with our existing software stack. This has been challenging and exciting work finding the right tools to help us achieve our goals.
Challenges and Assumptions
- We need to track model files and all related metadata for models like training metrics, date trained, etc. and store this information for a long time.
- The main reason for this is compliance and internal quality checks.
- Tracking models and all associated data is helpful in tracking performance over time, backtesting experiments and A/B testing.
- Due to security and compliance requirements we need to deploy our models in our own cluster, packaged within a microservice, on AWS.
- The specific Kubernetes clusters we deploy on our ML services were chosen as they are supported fully by our security and platform teams.
- In the future, we plan to explore serverless real-time inference.
- Our training code is stored on GitLab which is very securely locked down making it harder to integrate with a development platform like Databricks.
- GitLab also has our CI-CD pipeline to deploy ML services which makes it crucial to have optimal synergy between GitlLab and Databricks.
General Model Lifecycle
Experimentation and Development:
We use notebooks inside Databricks chiefly for experimentation, and these notebooks run on interactive clusters. Each cluster has a service account that has access to the requisite data. All model runs, associated performance metrics, and hyperparameters are stored in the model registry. The experiments and model registry are crucial to compare and contrast the performance of various models using a simple easy-to-use user interface.
We use the Databricks feature store to train our models. The features are created by sourcing data from various tables and data sources, and the feature store helps us abstract away the model training from the data collection operations.
Deployment and Re-training:
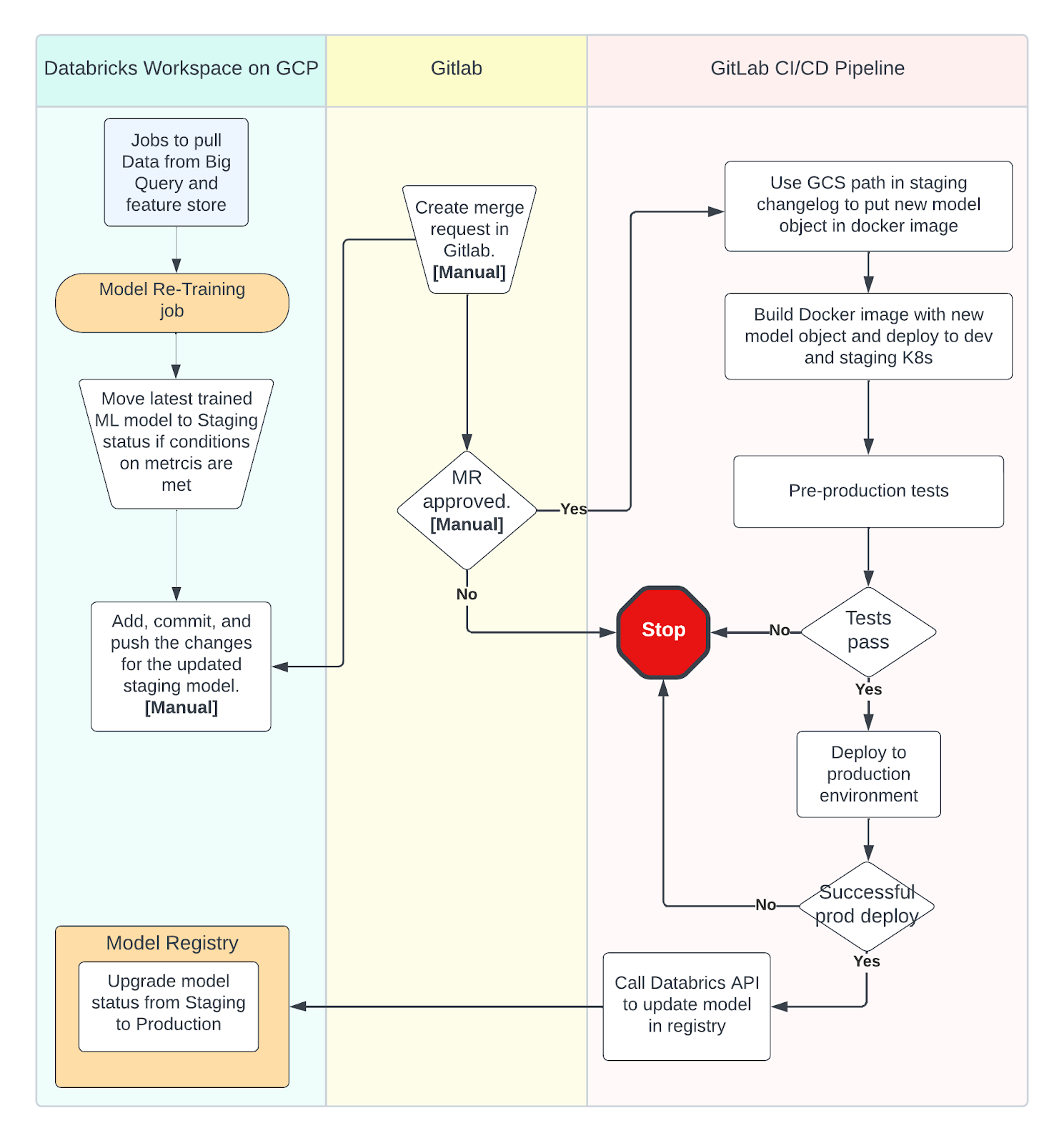
The model promotion and re-training cadence are explained in the steps below and illustrated in the flow diagram section.
Steps:
- A re-training job/workflow is set up in Databricks by an ML engineer that trains the model at a preset cadence. The model is trained on the latest available data, pulled from BigQuery and the Databricks feature store.
- Once the re-training job runs successfully, we obtain certain training metrics for the model, and if the model meets the basic requirements on each metric it is automatically promoted to staging in the experiment.
- The applied scientist updates the staging changelog to reflect the new model and model path in a new git branch, commits and pushes it back to GitLab. They will then create a merge request to be reviewed by others on the team.
- After the merge request is approved a deployment pipeline is started in GitLab. If it isn’t approved, then the applied scientist will work on the model again in Databricks.
- Unit, functional and other basic tests are run, and the service is packaged into a Docker image with the new model file. If these tests succeed the service containing the model is then deployed to our dev and staging Kubernetes environments.
- This is followed by pre-production tests, and if they succeed the service the new model is deployed to our production Kubernetes environment.
- As soon as this happens an API call is made to the experiment in our Databricks workspace to promote that model from Staging to Production and the production change log is also updated.
This re-training pipeline helps us quickly deploy new versions of a model and combat model drift. The re-training and deployment process utilizes the power of experiments and the model registry in Databricks while using our pipelines and tests in GitLab. While this is the general process for most of our models, some of the particulars of the deployment process and re-training cadence change from model to model.
Future Improvements:
- Currently, we only use the offline feature store in Databricks. We have identified certain use cases that require the online feature store and we will start using that in the near future.
- We are in the process of implementing many improvements on our post-deployment/ online model monitoring metrics that will help us quickly identify input/output and model drift.
Flow Diagram:
Tracking Models and Metrics with the Model Registry:
Having all our experimentation and re-training runs tracked by an experiment in Databricks and tracking the models in the model registry helps us quickly compare and evaluate models. Previously, the process was manual and limited the kind of models we could deploy. With this new process, we are not constrained in any way by the kinds of models we can use.
Using MLFlow Tracking and API
MLFlow tracking helps us accurately track ML experiment runs and associated trained models across GitLab, GCS and Databricks. We promote the model trained on the latest data to Staging if it meets certain metric requirements. Next we make an API call from Gitlab to the MLflow server in Databricks to upgrade the model to production after it passes human review. ML flow tracking and MLflow API help coordinate these actions with ease in spite of using different platforms for model development, testing and deployment.
The human review helps us stay in control of deployments but we are planning to reduce the need for human review by improving the set of model metrics we track which will give us more confidence in the models that we deploy. MLflow tracking is helping us greatly in this aspect too.
Conclusion
Ripple has deployed machine learning across a number of its products to serve customers at scale and cost effectively. Databricks experiments, model registry and MLflow tracking allowed us to train, compare and deploy models in real-time.
- Model registry and experiments help us organize all of our experimentation runs. This makes comparing and analyzing our models easy. Before the model registry we had no way to keep track of all the experiment runs and model versions. It turned a manual, time intensive and error prone process into a streamlined, fast and automated process.
- ML flow tracking and ML flow APIs help with updating model stages and tags across various platforms. This allows us to keep using Gitlab and Databricks simultaneously with some integration work.
- Once we had our GCP infrastructure in order we were able to get 4 teams working on 3 different model lines at Ripple onto Databricks in a matter of two months.